STAM:针对大型分布式应用系统的拓扑自动检测方法
- Sheng Wu 吴 晟
- wusheng@apache.org
- 翻译:BZFYS(327568824@qq.com), Yanlong He 何延龙 (heyanlong@apache.org)
摘要
对大型分布式系统进行监视,可视化和故障排除是一项重大挑战。当今使用的一种常见工具是分布式跟踪系统(例如Google Dapper)[1],它基于跟踪数据检测拓扑和度量。当今拓扑检测的一大局限性在于,只能根据给定的时间窗口的跟踪数据来推断服务之间的依赖关系。这会导致更多的延迟和内存使用,因为在高度分布式的系统中,每个客户端和服务端追踪信息都必须在数百万个随机RPC请求中进行匹配。更重要的是,如果客户端和服务器之间的RPC持续时间长于先前的设置时间窗口或跨越两个窗口,则它可能无法匹配。
在本论文中,我们提出了STAM(流拓扑分析方法)。在STAM中,我们可以使用自动检测或手动检测机制在客户端和服务器端截取和操纵RPC。对于自动检测,STAM在runtime处理应用程序代码,例如Java代理。因此,此监视系统不需要应用程序开发团队或RPC框架开发团队修改任何源代码。STAM将客户端使用的RPC网络地址,服务名称和服务实例名称注入RPC上下文,并将服务器端服务名称和服务实例名称绑定为客户端使用的该网络地址的别名 。将依赖性分析从导致阻塞和延迟的机制中解放出来,
STAM已在Apache Software Foundation的一个开源APM(应用程序性能监视系统)项目Apache SkyWalking [2]中实施,该项目已在许多大型企业中广泛使用[3],其中包括阿里巴巴,华为,腾讯,滴滴,小米,中国移动和其他企业(航空公司,金融机构等)在生产环境中支持其大型分布式系统。它具有更好的水平扩展能力,从而显着降低了负载和内存成本。
介绍
监控高度分布式的系统(尤其是使用微服务体系结构)非常复杂。许多RPC,包括HTTP,gRPC,MQ,缓存和数据库访问,都在单个客户端请求之后。让IT团队了解数千个服务之间的依赖关系是整个分布式系统可观察性的关键特征和第一步。分布式跟踪系统能够收集跟踪,包括所有分布式请求路径。逻辑上已将依赖关系包括在跟踪数据中。分布式跟踪系统,例如Zipkin [4]或Jaeger Tracing [10],提供了内置的依赖关系分析功能,而且有许多分析功能都基于此。这种分析至少存在两个局限性:实时性和一致的准确性。
服务级别和服务实例级别的依赖分析过程中,由于分布式应用程序系统依赖关系的可变性,需要很强大的实时性保障。
服务是具有相同功能或代码的实例的逻辑组。
服务实例通常是操作系统级别的进程,例如JVM进程。服务和实例之间的关系是可变的,具体取决于配置,代码和网络状态。依赖关系可能会随着时间而改变。

图1,在传统的基于Dapper的跟踪系统中生成的span。
Dapper论文中的span模型和现有的跟踪系统(例如Zipkin仪器模式[9])只是将span id传播到服务器端。由于这种模型,依赖性分析需要一定的时间窗口。关系分析同时依赖从客户端和服务端收集到的追踪数据。因此,分析过程必须等待客户端和服务器span在同一时间窗口中匹配,才能输出结果Service A依赖于Service B。因此,RPC请求持续时间必须在时间窗口内;否则,将无法分析出服务关系数据。在生产中,有时必须将窗口持续时间设置为3-5分钟,使得拓扑分析无法在秒级做出反应。另外,由于基于时间窗口的设计,如果一侧涉及到长时间任务,它不能轻易达到一致的精度。因为,为了使分析尽可能快,所以分析时间少于5分钟。但是,如果分析不完整或跨越两个时间窗口,则某些span将无法与其父级或子级匹配。即使我们添加了一种机制来处理前一阶段剩余的span,仍然必须放弃一些机制以保持数据集大小和内存使用合理。
在STAM中,我们使用新的分析方法介绍了新的span和上下文传播模型。这种新模型将客户端使用的对端网络地址(IP或主机名),同时,客户端将自己的服务实例名称和客户端服务名称添加到上下文传播模型中。然后,依托RPC调用从客户端传递到服务器,就像现有跟踪系统中的传递原始Trace ID和Span ID一样,并将其收集在服务器端span中。新的分析方法可以轻松地直接生成客户端-服务器关系,而无需等待客户端span。它还将客户端使用的对端网络地址设置为服务端服务的一个别名。在跨集群节点数据同步后,客户端span分析也可以使用此别名元数据直接生成客户端-服务器关系。通过在Apache SkyWalking中使用这些新模型和方法,我们不再依赖基于时间窗口的分析方法,在低于5秒延迟的条件下,准备地进行拓扑图分覅。
Span Model(新的跨度模型)和Context Model(上下文模型)
跟踪系统的传统范围包括以下字段[1] [6] [10]。
- Trace ID,代表整个跟踪。
- Span ID,代表当前span。
- 一个operation name,描述此span执行的操作。
- start timestamp(开始时间戳)。
- finish timestamp(完成时间戳)。
- 当前Span的Service和Service Instance名称。
- 一组零个或多个键值对组成的的span tag。
- 一组零个或多个span日志,每个span日志本身就是与时间戳配对的key:value映射。
- 引用零个或多个因果相关的span。参考包括parent span id和trace id。
在STAM的新span模型中,我们在span中添加以下字段。
Span type(跨度类型): 枚举类型,Exit,Local和Entry。Entry和Local适用于网络相关的库中。输入范围代表服务器端网络库,例如Apache Tomcat [7]。Exit spans代表客户端网络库,例如Apache HttpComponents [8]。
Peer Network Address:(对端网络地址): 远程“Address”,适用于exit和entry的span。在“Exit spans”中,对端网络地址是客户端库访问服务器的地址。通常,这个字段通常在许多跟踪系统中是可选的。但是在STAM中,我们在所有RPC情况下都需要它们。
Context Model(上下文模型):用于将客户端信息传播到原始RPC调用所携带的服务器端,通常在header(例如HTTP header或MQ header)中传播。在旧的设计中,它带有客户端span的Trace ID和Span ID。在STAM中,我们增强了此模型,添加了父服务名称,parent service instance name(父服务实例名称)和peer of exit span.(出口范围的对等点)。名称可以是文字字符串。所有这些额外的字段将有助于消除流分析的障碍。与现有的上下文模型相比,它使用更多的带宽,但是可以对其进行优化。在Apache SkyWalking中,我们设计了一种注册机制来交换代表这些名称的唯一ID。结果,在RPC上下文中仅添加了3个整数,因此在生产环境中带宽的增加至少小于1%。
两种模型的变化可以消除分析过程中的时间窗口。Server-side span分析增强了上下文感知能力。
新的拓扑分析方法
STAM核心的新拓扑分析方法是以流模式处理span。server-side span(也称为entry span)的分析针对包括parent service name(父服务名称),parent service instance name(父服务实例名称)和exit span的peer信息。因此,分析过程可以得出以下结果。
-
使用exit span的peer做为当前服务和实例的别名。创建
Peer network address <-> service name和peer network address <-> Service instance name别名。这两个将与所有分析节点同步并保存在存储中,从而允许更多分析处理者拥有此别名信息。 -
生成
parent service name -> current service name和parent service instance name -> current service instance name两种关系数据,除非发现当前已经存在还有另外一个不同的Peer network address <-> Service Instance Name映射关系。在这种情况下,仅生成peer network address <-> service name的关系和peer network address <-> Service instance name的关系。
为了分析client-side span(exit span),可能存在三种可能性。
-
exit span中的对等方已经具有从步骤(1)进行的服务器端范围分析所建立的别名。然后使用别名来代替peer信息,并产生的流量
current service name -> alias service name和current service instance name -> alias service instance name。 -
如果找不到别名,那么只需为
current service name -> peer和current service instance name -> peer生成流量。 -
如果
peer network address <-> Service Instance Name可以找到的多个别名,则继续为current service name -> peer network address和current service instance name -> peer network address生成流量。
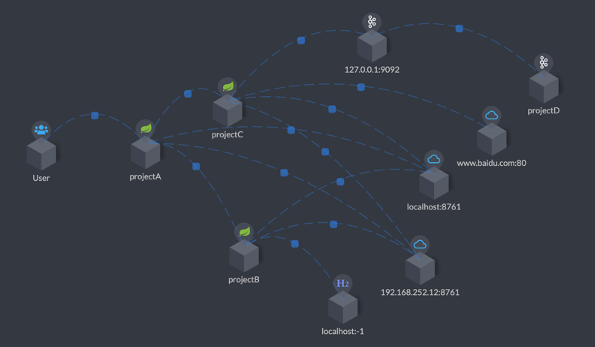
图2,Apache SkyWalking使用STAM来检测和可视化分布式系统的拓扑。
评价
在本节中,我们将在几种典型情况下评估新模型和分析方法,在这些情况下,旧方法会失去及时性和一致的准确性。
-
- 在线新服务或自动扩展
新的服务可以由开发团队随机地添加到整个拓扑中,也可以通过某种扩展策略自动将容器操作平台添加到整个拓扑中,例如Kubernetes [5]。在任何情况下都无法手动通知监视系统。通过使用STAM,我们可以自动检测新节点,并保持分析过程畅通无阻,并与检测到的节点保持一致。在这种情况下,将使用新的服务和网络地址(可以是IP,端口或两者)。peer network address <-> service映射不存在,将首先生成client service -> peer network address的流量并将其持久化在存储中。生成映射后,可以在分析平台中识别,生成和聚合客户端服务到服务器服务的其他流量。为了在生成映射之前填补一些流量的空白,我们要求在查询阶段再次进行peer network address <-> service映射转换,以将client service->peer network address和client-service合并到server-service。在生产中,整个SkyWalking分析平台部署的VM数量少于100,在它们之间的同步将完成少于10秒,在大多数情况下仅需要3-5秒。在查询阶段,数据至少要在几分钟或几秒钟内汇总。查询合并性能与生成映射之前发生的流量无关,仅受同步持续时间的影响,此处仅3秒。因此,在分钟级别的聚合拓扑中,它仅在整个拓扑关系数据集中添加1或2个关系记录。考虑到每分钟有500多个关系记录的100多个服务拓扑,此查询合并的有效负载增加非常有限且负担得起。该功能在大型高负载分布式系统中非常重要,因为我们无需担心其扩展能力。在某些fork版本中,为了永久地消除查询阶段的额外负载,在检测到新的对等映射后,他们选择更新现有的client service->peer network address到client-service到server-service,以便永久消除查询阶段的额外负载。
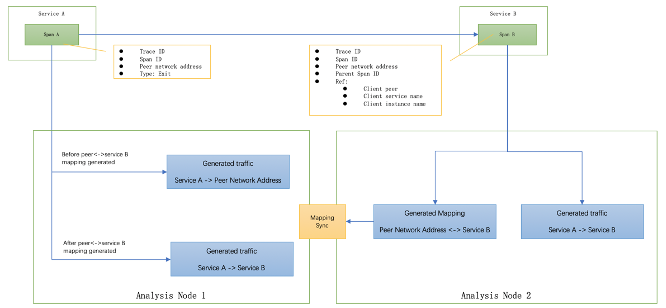
图3,使用新的拓扑分析方法进行span分析
-
- 现有未配置节点
在这种情况下,每种拓扑检测方法都必须起作用。在许多情况下,生产环境中存在无法被监控的节点。其原因可能包括:(1)技术限制。在某些使用golang或C ++编写的应用程序中,Java或.Net中没有简单的方法来由代理进行自动检测。因此,可能不会自动检测代码。(2)MQ,数据库服务器等中间件未采用跟踪系统。分布式追踪这些中间件是非常耗时或者时间困难的。(3)第三方服务或云服务不支持当前跟踪系统的工作。(4)缺乏资源:例如,开发人员或操作团队缺乏时间完成探针安装或者修改代码。
即使客户端或服务器端没有探针,STAM也可以正常工作。它仍然保持拓扑尽可能准确。
如果未安装客户端探针,则server-side span将不会通过RPC上下文获得任何引用,因此,它将仅使用peer来生成流量,如图4所示。
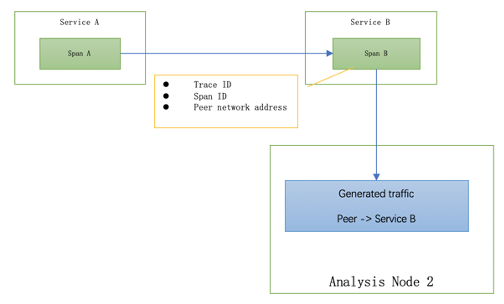
图4,没有客户端探针时的STAM流量生成
如图5所示,在另一种情况下,由于没有server-side span,因此client span分析不需要处理这种情况。STAM分析核心只是简单地不断生成client service->peer network address。由于没有生成的peer network address的映射,因此没有合并。
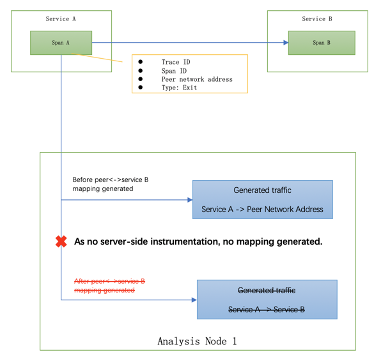
图5,没有服务器端探针时的STAM流量生成
-
- 具有报头转发能力的未配置节点
除了我们在(2)未配置节点中评估的情况外,还有一种复杂而特殊的情况:被检测的节点具有将header从下游传播到上游的能力,通常在所有代理中,例如Envoy [11],Nginx [12] ],Spring Cloud Gateway [13]。作为代理,它具有将所有header从下游转发到上游的功能,以将某些信息保留在header中,包括tracing上下文,身份验证信息,浏览器信息和路由信息,以使它们可被位于proxy后面的业务服务访问,例如Envoy路由配置[14]。当无论什么原因,某些代理无法安装探针时,它都不应该会影响拓扑检测。
在这种情况下, proxy address在客户端使用,并通过RPC上下文作为peer network address,并且代理将其转发到其他上游服务。然后,STAM可以检测到这种情况并生成代理作为推测节点。在STAM中,应为此网络地址生成多个别名。在检测到这两个并同步到分析节点之后,分析核心知道客户端和服务器之间至少有一个未配置的服务。因此,它将生成client service->peer network address,peer->server service B和peer network address->server service C的关系,如图6所示。。
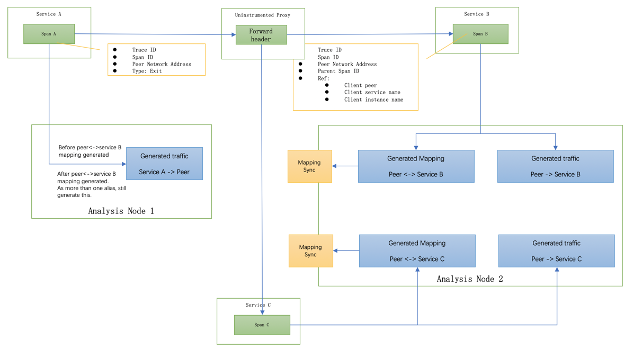
图6,代理无法被监控时,STAM流量的生成
结论
这个论文介绍了STAM,据我们所知,STAM是分布式跟踪系统的最佳拓扑检测方法。它取代了基于时间窗口的拓扑分析方法,用于基于跟踪的监视系统。它永久和完全地消除了,使用基于时间窗口分析方法中的磁盘和内存资源成本,并消除了水平扩展的障碍。Apache SkyWalking是一个STAM实现,被广泛用于监视生产中的数百个应用程序。其中一些每天生成超过100 TB的跟踪数据,并为200多种服务实时生成拓扑。
致谢
我们感谢Apache SkyWalking项目的所有贡献者,感谢他们对此分析模型提出的建议,实现STAM的代码贡献以及在生产环境中使用STAM和SkyWalking,并提供反馈。
许可证
这篇论文和STAM使用Apache 2.0许可协议
参考文献
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure, https://research.google.com/pubs/pub36356.html?spm=5176.100239.blogcont60165.11.OXME9Z
- Apache SkyWalking, http://skywalking.apache.org/
- Apache Open Users, https://github.com/apache/skywalking/blob/master/docs/powered-by.md
- Zipkin, https://zipkin.io/
- Kubernetes, Production-Grade Container Orchestration. Automated container deployment, scaling, and management. https://kubernetes.io/
- OpenTracing Specification https://github.com/opentracing/specification/blob/master/specification.md
- Apache Tomcat, http://tomcat.apache.org/
- Apache HttpComponents, https://hc.apache.org/
- Zipkin doc, ‘Instrumenting a library’ section, ‘Communicating trace information’ paragraph. https://zipkin.io/pages/instrumenting
- Jaeger Tracing, https://jaegertracing.io/
- Envoy Proxy, http://envoyproxy.io/
- Nginx, http://nginx.org/
- Spring Cloud Gateway, https://spring.io/projects/spring-cloud-gateway
- Envoy Route Configuration, https://www.envoyproxy.io/docs/envoy/latest/api-v2/api/v2/rds.proto.html?highlight=request_headers_to_